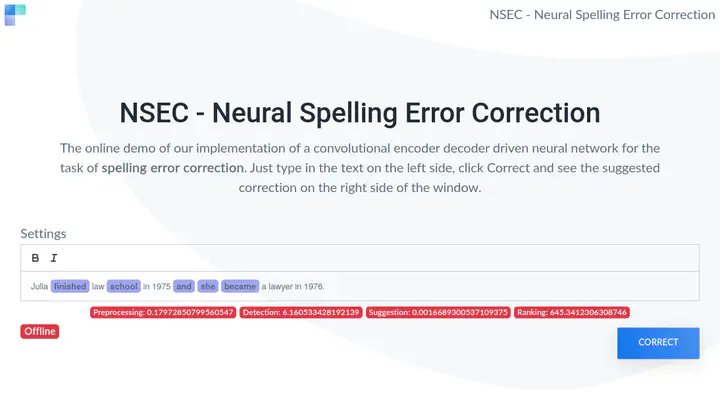
 Example of NSEC in action
Example of NSEC in action
Generating a spelling error corpus, as previously done, is only one part. The other one is the correction of those errors, which will be handled by a tool developed during a research fellowship. As the correction of malformed sentences can be seen as some sort of translation task from noisy english to correct english, my first approach was based on techniques known from the field of neural machine translation (NMT). Although this approach worked well I dislike the concept of relying on a black box approach where one don’t know what is happening inside (beside the point of fine-tuning such an End2End network), which brought we to the Neural Spelling Error Correction framework, for short NSEC.
Overall Architecture
As already mention, I dislike the concept of black box approaches, so the first step was the identification of all subtasks for the task of spelling correction. An top-down overview of the whole whole system architecture of NSEC can be seen in Figure 2. Within the subsequent sections we will describe each of those module in more detail with (1) all preprocessing steps performed on the input sequence in 4.3, (2) the error detection step in 4.4, (3) the correction candidate suggestion of erroneous tokens in 4.5, and (4) the ranking of those generated correction candidates in 4.6.
Phase 1: Preprocessing
Before performing anything on the provided data it will be enriched with additional information first.
Phase 2: Error Detection
Although some erroneous tokens are already filtered out by the Common-Typo Identifier of the preprocessing step we added an additional submodule which is solely responsible for identifying potentially erroneous tokens. As seen in Figure ??, instead of e.g. solely using character-level embedding of the sequence we combine multiple different embeddings (1). This has the advantage that words that are known to the word-level embedding are embedded as such, if the word is unknown the word-level embedding will be set to UNKNOWN. In that case we still have the information about the character-level embedding that can be used to determine whether this word is erroneous or not. In addition to thecharacter-level embeddings of each token we also generate the phonetic information for each token, which will give us further en- hanced information about the acoustic pattern of each token. As the capitalisation information of the words was removed during the lookup within the word embedding we separately add information as a feature vector whether the observed word is of any of the types all_capitalised, first_capitalised, lowercase, mixed_capitalisation, or no_info.
Phase 3: Suggestion Generation
For the current initial implementation of the suggestion module we are using a single sub-step for proposing correction candidates Norvig For the first determination of potential replacement candidates for each of the flagged tokens we use an adapted version of Peter Norvigs spelling correction tool. We modified the original approach in such a way that we get a list of all tokens that are within an edit distance of 2 of the original token and further filter out all alternative tokens that are not part a predefined language dictionary of known words. The list of potential correction candidates is then enriched with these candidates. Through this we are able to receive, e.g. for the token shool the correction candidates school, shoot, shook, and shoal and for becmme the suggestions became and become.
Phase 4: Ranking
The last step is the generation of all permutations of all correction candidates and filling the sentence with those permutations. For the ranking itself I used a standard BERT language model which returns the perplexity of all sentences as its result. Perplexity is a metric used to judge how good a language model is. For the identification of the correct replacement candidates I used it as an indirect measurement of the correctness.
This means: The lower the perplexity, the better do the correction candidates fit into the sentence itself.
Markus Näther
Machine Learning Engineer
My research interests include distributed robotics, mobile computing and programmable matter.